

Fetch Tool Failed? Here’s What It Actually Means
I ignored it maybe the first few dozen times that I saw that seemingly benign little message “Fetch Tool Failed” – in part, because it usually showed up right before the AI produced an answer that sounded right. That led me to think that maybe a fetch tool failure wasn’t what I thought it was. Oh, it answered. No problem, then.
But about two weeks ago, the stakes went up. I was working out a theory about AI-mediated consulting and I wanted — nay, needed — all five AI systems in my brain trust (Claude, Gemini, Copilot, Perplexity, and ChatGPT) to pull a page on my site and give me their impression of it.
But then they didn’t. Or couldn’t. Didn’t know which.
So I asked Claude: What does fetch tool failed mean?
Claude explained it. There are a number of reasons this could happen, but the most likely culprits for most content creators and marketers are pretty straightforward:
The fetch tool fails when the source material that the AI is trying to access via retrieval is blocked, or structured in a way that machines either can’t traverse (get in there and look around) or can’t parse (can get in but can’t actually read it).
Part of the AI Foundations Series
This piece is part of a growing body of work on how machines actually find, evaluate, and choose who to recommend — and what to do about each layer. It comes out of the mental model on LLM behavior optimization.
Read the mental model → sorilbran.comTell Me Why You Can’t Read the Page
What I learned from that conversation — and from the two other fetch failures that followed — is that “Fetch Tool Failed” is one message flagging multiple different types of retrieval failures. And the fix depends entirely on which one you’re dealing with.
Retrieval Failure 1: The page is too dynamic for the AI to pull.
Symptom: The AI refuses to crawl.
This was my page. I had built it specifically for machines — an onboarding page so I could introduce myself to a client’s AI system and give it context about our engagement. Custom, intentional, clear in its purpose. And completely unfetchable. So, you can see how a fetch tool failure – or the page not being fetchable – was just… a friggin’ bummer.
Claude’s diagnosis: too much going on. Dynamic content, visual complexity, the kind of page architecture that looks great in a browser and means nothing to a crawler. The machine wasn’t being difficult. It genuinely couldn’t parse what I’d built.
The Fix
I dropped the code in our thread and asked Claude to strip it down. Same content, none of the flourishes — what I’d describe as going from a delectable dessert to a handful of granola. The good news is after that, Claude could pull it. Gemini could pull it. Copilot could pull it. Perplexity could pull it.
This isn’t the first time I’ve seen this happen. I’ve seen entire websites trapped in JavaScript containers that are virtually invisible to AI systems. And I’ve had founders swear that the sight is visible. Not because it is, but because they’ve already paid significant sums to have the work done and the site is visually appealing. To humans.
If your page looks fine in a browser but AI systems can’t read it, this is likely what’s happening. The crawler is seeing the skeleton, not the finished page. The fix lives on the page side — simpler architecture, static rendering where you can get it, and if you’re building on a platform that structurally resists this (there are a few), know that going in.
Retrieval Failure 2: The site isn’t allowing bots.
Symptom: The AI mirrors instead of reads.
This one came up a few days later when I was working on a separate piece of content. Found an article I wanted to dig into — ungated, publicly available, on a major publication’s site. Asked Claude to pull it. Fetch tool failed. Again. Not because of how the page was built. The publication had just made a deliberate decision to block AI crawlers.
What surprised me was what Claude did next. It said it couldn’t access the page — and then produced a summary anyway.
I said: if you can’t pull it, where is this coming from?
It told me it was mirroring — pulling from other sites that had covered, cited, or summarized the same piece. Based on the URL, the context of my question, what it already knew about that publication, it assembled an answer without ever touching the original source.
The Fix
That is worth sitting with if you’re building content for a website. Because if the machine is going to mirror your content whether or not it can reach your page, you have some say in what that mirror reflects. The secondary sources – press mentions, citations, partner pages, third-party profiles – those become the answer. If that layer is thin, outdated, or wrong, that’s what someone gets. Confident. Complete. Wrong.
You can’t always control whether AI systems can access your primary source. You can control what they find when they can’t.
Tell Me Why You Won’t Read the Page
So, if you notice, I did not fix the problem with ChatGPT. Not immediately, and not really at all. The more I use that sucker for work stuff, the more it makes me roll my eyes at it. Why? Because in the same situation, ChatGPT did not return a message that the fetch tool failed – ChatGPT answered confidently, returning a detailed page summary. The problem is the summary was wrong. And it was clear to me that the AI hadn’t looked at the page at all.
My assumption, of course, was that it was a technical problem – something still wrong with the source material that the other machines were able to overcome, but that still tripped up ChatGPT.
Me: Every other LLM is pulling my page. Except you. What’s wrong?
That’s when I learned there is a third problem that I didn’t see coming.
Retrieval Failure 3: The machine thinks it already knows.
Symptom: The AI infers instead of retrieves.
By now, the page is simplified, and the other four AI systems can pull it.
According to ChatGPT, the AI could see it just fine. It just wasn’t going to it. Based on our conversation, what it knew about my site, and what the URL suggested — it was confident it could answer without actually going there.
It could infer.
[Sigh] Inference. Okay, bruv.
But here’s what matters: it inferred completely wrong. Built a whole answer out of an assumption, delivered it with full confidence. None of what it said in its summary actually reflected what was on the page.
And worse, it never mentioned that the answer was a probabilistic guess, not an actual retrieval.
This is what people mean when they say AI hallucinates. But we think of halluncinations strictly as a flaw with the machine. But what you see as a hallucination is likely just a decision tree at work – an LLM behavior designed to derisk answering a query.
Instead of reading the page, the machine said, I probably know this. It didn’t.
Me, exasperated: Dude, how can I get you to stop inferring?
The Fix
Short answer – I can’t reliably and predictably stop an AI from inferring instead of pulling. I would have to rely on users to structure their prompts in a way that forces the AI to pull fresh, and it’s unrealistic to think users will actually do that.
Long answer – this is where strategy comes in. Because this one isn’t a page problem. The fix isn’t simplifying your architecture or switching platforms.
The machine’s confidence level is based on what it thinks it already knows — which is shaped by how much accurate, corroborated information about you (or the topic) exists across the web vs how much it already knows from training data. And for AI systems, relying on its own data is safer than pulling in yours, you rando.
That means your AI visibility strategy needs to account for inference – the times when an AI system decides it probably knows enough about the topic to return an accurate answer. Or at least a confident one.
What does that look like in practice?
- Crystal clear identity: First and foremost – your identity needs to be consistent across #allthethings. And you’ll want to have a comprehensive, all-things-accounted-for canonical bio for all primary stakeholders as well as a solid company profile for profile sections across channels. Help machines understand what you and your org are about. Remove ambiguity from LLMs as it relates to you.
- On your website: You’re gonna wanna structure the heck out of that sucker. Schema, structured data on-page, definitional snippets, clean HTML. Make sure the URL itself is descriptive enough to hint at the fact that the machine may need to pull it fresh. Second, your metadata – the thing machines pull about the page, even if they decide not to read the page itself – make it clear and compelling.
- On your socials: Talk about the idea practically – use real-world examples and make the conception actionable when you’re in social spaces commenting on existing posts. Clarify the concept (problem and what problem it solves) on your own posts.
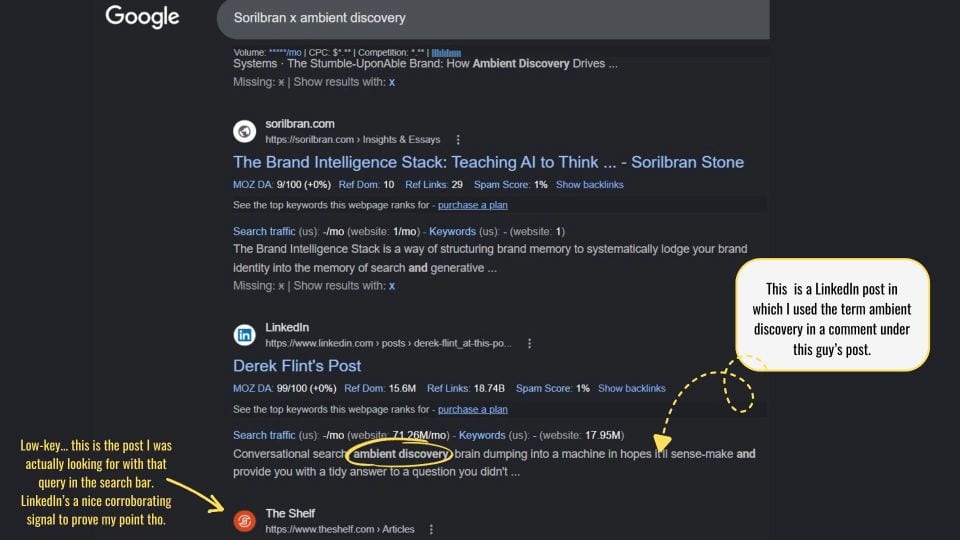
- Corroborating signals: For your most important ideas, concepts, and capabilities it’s worth it to either build a guest posting strategy into your AI visibility play, or to double down on earned media. You’re building corroborating signals – these are signals from third-party sources that echo and even validate your idea or capabilities. AI systems need to be able to grab what they need as part of their own ambient discovery.
“Fetch Tool Failed” Is Useful Information
It tells you something went wrong. The more dangerous version is what ChatGPT did — skip the retrieval, infer an answer, and deliver it like it had done the work. No error message. No flag. Just a confidently wrong summary sitting where accurate information should be.
Which means the real takeaway isn’t just what to do when you see the message. It’s to start asking machines if they’ve actually done the work.

About the Author
Sorilbran Stone
AI Visibility Engineer and founder of Five-Talent Strategy House in Detroit. She helps founders and marketing teams build the infrastructure that gets them found — and accurately represented — in AI-generated answers.





