

AI REcommendations: Legibility, Eligibility, and Extractability
Legibility, Eligibility, and Extractability are the three conditions content must meet in order to become recommendable by AI systems. These three function as interdependent conditions, not interchangeable priorities,.This is the LEE Mental Model for AI recommendability.
Part of the AI Foundations Series
This piece is part of a growing body of work on how machines actually find, evaluate, and choose who to recommend — and what to do about each layer. It comes out of the mental model on LLM behavior optimization.
Read the mental model → sorilbran.comTHIS MENTAL MODEL WAS UPDATED May 7, 2026: If you had asked me about this a few days ago, I would have said there are three tiers: Legibility, Eligibility, and Recommendability. And I would have described them as sequential gates, not interdependent conditions.
But recommendability got stuck in my craw because I couldn’t resolve it neatly in my mind. Recommendable like how? To whom? Which parts? The idea of being recommendable seems more abstract than definite. And answers in LLMs are heavily shaped by the context the machine has about the user. So “recommendabilty” becomes quite subjective.
I saw that. But I also knew that beyond Legibility and Eligibility, there was another door to push through. Two days ago (a day after I originally published this article), extractability emerged as a better model for recommendability. Extractability gives you the condition necessary for the function of recommendability. And that’s what I think is most valuable here – understanding the conditions necessary to position LLMs as sales channels.
So, here’s what I keep seeing when I do visibility audits for founder-led companies. The content is solid. The company has genuine expertise, processes that deliver results, and wins under their belt – whether that’s been documented or not. But when I ask an AI system to describe them, it either hedges, gets a big thing wrong, lines them up in a row of can’t-tell-them-apart competitors, or surfaces someone else entirely.
And when I dig in, the problem is almost never the thing they’ve asked me to fix (usually recommendations). They’ve done all the right things. But they’ve usually been busy optimizing for at least one aspect of machine visibility, but not all three. Something, inevitably remains under-built.
This is one of those concepts that sat outside my conscious mind for a while. Like the answer that just sits on the tip of your tongue but doesn’t get clear enough to say out loud. It was cycling in my mind nonstop for weeks before I stumbled upon a mental model that made sense of what I’m seeing both as a consultant and in the wider market.
Updated May 7, 2026
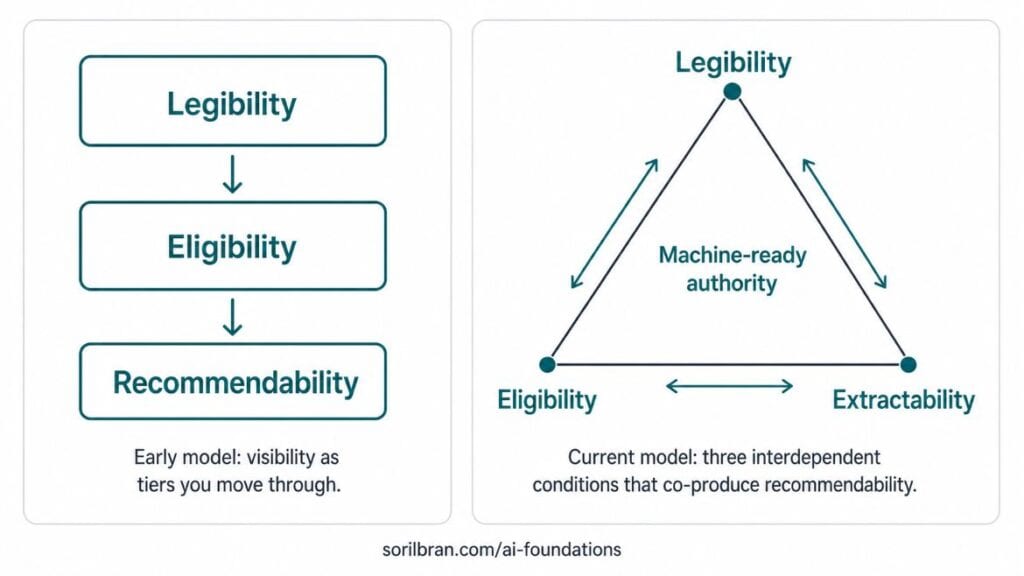
This framework started as a sequential tiers model. I’m now treating it as a more useful interdependent system, and replacing recommendability with extractability.
And that’s that AI visibility isn’t one problem. It’s three problems, stacked in sequence, where each one has to be solved before the next one can be addressed.
And that’s that AI visibility isn’t one problem. It’s three problems, interdependent, where each one has to be solved to prevent degradation in the others.
Legibility is non-negotiable. Without it, the other two won’t work. But they are mutually reinforcing conditions.
Three AI Visibility tiers – Legibility -> Eligibility -> Extractability
And once you see it, you can’t un-see it. The session where it landed —if you want the origin story — is here.
Why Each Condition is Non-Negotiable: Legibility Builds Eligibility Builds Extractability Builds Eligibility Builds Legibility
Legibility, Eligibility, and Extractability are the conditions you create for machines to understand your entity, trust your capabilities, and be able to safely extract your content. Clearing one does not automatically clear the next, and attempting to optimize for extractability before the other two conditions are met wastes resources and produces inconsistent results.
Here’s what happens at each failure point.
If Legibility isn’t solved, the machine can’t reliably identify you. It might know a version of you — outdated, fragmented, or confused with someone else. Everything built on top of that leaks. Press mentions get attributed to the wrong entity. Content earns credibility for a version of you that doesn’t match current reality.
If Eligibility isn’t solved, the machine identifies you but doesn’t trust you enough to include you. It hedges. She claims. According to their website. Details may vary. That language isn’t filler — it’s the machine’s confidence score made visible. Hedged claims don’t get recommended.
If Extractability isn’t solved, the machine knows you and trusts you but can’t use you. The content is well-written, the expertise is real, the proof is documented — but it’s not structured in a format the machine can extract and cite. So it reaches for someone else.
Three problems. Three fixes. The diagnostic is figuring out which one you’re actually dealing with before doing any more work.
CONDITION 1: What Is Legibility in AI Visibility Strategy?
Can the machine identify you accurately without visiting your website?
Legibility is the degree to which an AI system can identify, parse, and connect the information that constitutes a person or business as a coherent entity. A legible entity is one the machine can describe accurately, consistently, and without inference.
This is the first brick. It’s the layer I spend the most time on with clients — and the one that’s most often missing entirely. You can see what that looks like in practice in this active disambiguation engagement.
A legible entity is one the machine can describe accurately, consistently, and without inference. It knows your name — the same name, across every surface where you appear. It knows your role. It knows what you do, who you serve, and what makes you distinct. And it can construct that picture from the aggregate signal of everything published about you and by you — not just from your own website.
The failure isn’t usually that someone hasn’t done the work. It’s that the work was never structured in a way machines can read. A founder who has published under three different name variations, or whose LinkedIn and website tell different stories about what they do, or whose content is attributed to “the team” rather than a named individual — that’s an illegible entity. Not because the expertise isn’t real. Because the machine can’t assemble the pieces.
What Legibility Requires
A canonical bio plus a consistent, two to three sentences, appearing identically across every published piece and every platform profile. This is the machine’s primary anchor for connecting content to a named entity. The full guide on building a canonical bio is here.
Schema markup. Article schema, Person schema, Organization schema. The structured data layer that tells machines explicitly what type of content this is and who authored it.
Cross-platform consistency. Same name, same title, same specialization — everywhere your name appears. Inconsistency is the most common Legibility failure and the easiest to fix.
An entity identity page that introduces the person, not just the services. A services page tells the machine what you offer. An About page tells it who you are. Those are different things and only one of them builds Legibility.
This is the layer the Minimum Viable Knowledge Graph is built to address — mapping the five nodes of your entity structure – identity, specialization, audience, expertise, and proof – surfacing where the architecture is thin before any content strategy work begins.
The Legibility Failure Mode: When Work Leaks Instead of Compounds
You build for Eligibility and Extractability — content, press, optimized architecture — and the machine attributes it to a fragmented version of you that doesn’t match current reality. Or to someone else with a similar name who has stronger entity signals. The work doesn’t compound. It leaks.
Condition 2: What Is Eligibility in AI Visibility Strategy?
Does the machine consider you credible enough to include in an answer?
Eligibility is the degree to which an AI system assesses an entity as credible, authoritative, and trustworthy on a given topic. An eligible entity is one the machine determines belongs in the answer set for a specific query — not just one that can be identified, but one that has earned the right to be included.
Legibility tells the machine who you are. Eligibility tells it whether you belong in the answer. Those are genuinely different questions with genuinely different answers.
The thing to understand about Eligibility is that what you say about yourself is a claim. What others say about you is evidence. The machine weighs them differently. It checks whether your self-description is validated externally. If the only place your expertise appears is your own website, that’s a single-source dependency. And single-source dependencies produce hedging language.
This is where E-E-A-T lives — Experience, Expertise, Authoritativeness, Trustworthiness — but not as a checklist. It’s the machine’s aggregate reading of everything it can find about you, weighted toward what credible external sources have already confirmed.
What Eligibility Requires
Corroboration. Third-party sources confirming what you claim about yourself. Press mentions, guest articles on credible publications, podcast appearances, being cited in industry reports. The machine is checking whether your self-description is validated externally.
Documented outcomes. Specific case studies — client type, intervention, measurable result, timeline. Generality is invisible to machines. Specificity is what makes a case study readable and citable.
Track record. Consistent, dated content on the same topic cluster over time. One article is a claim. Twelve articles over eighteen months is a pattern the machine reads as expertise.
Anecdotal evidence. First-hand experience documented in content — specific scenarios that could only come from someone who has actually done the work. A machine reading a specific anecdote tied to a named outcome reads it as proof of direct experience.
A Note on Compensating Signals
Traditional authority signals — VC funding, research budgets, mainstream press — are structurally inaccessible to a lot of the founders I work with. That’s not a personal deficit. It’s a structural gap in how authority has historically been assigned and documented.
Compensating signals aren’t a workaround — for these clients, they’re the strategy. Notion Marketplace listings. Amazon author pages. Local press. Industry association citations. Podcast networks. Community platforms. These do real work in the machine’s eligibility calculus when they’re built deliberately and consistently. The Compensating Signals framework goes deeper on this if you want the full breakdown.
The Eligibility Failure Mode: When Hedging Replaces Recommendation
The machine knows who you are, but hedges — according to their website, she claims, the company states. Hedged claims don’t get recommended. They get footnoted. And that hedging language is diagnostic data, not noise. More on that below.
Condition 3: What Is Extractability in AI Visibility Strategy?
When the machine is constructing an answer, can it use you?
Extractability is the degree to which an AI system that could select a specific entity to include in a generated answer is actually able to safely grab content from that entity’s content (website, LinkedIn, Instagram, Facebook, Substack, Medium, etc). This is content an AI system would see as distinct from merely recognizing the entity as credible. A recommendable entity is one whose content is structured, specific, and citable enough that the machine can extract and use it to answer a precise question — and attribute it with confidence rather than with hedging language.
I have a great example of this that I stumbled upon recently that I talked about in this LinkedIn post.
In my downtime, I started wondering about the release date of AC/DC’s “Thunderstruck.” Did a little digging and pulled up Google’s knowledge panel on the song.
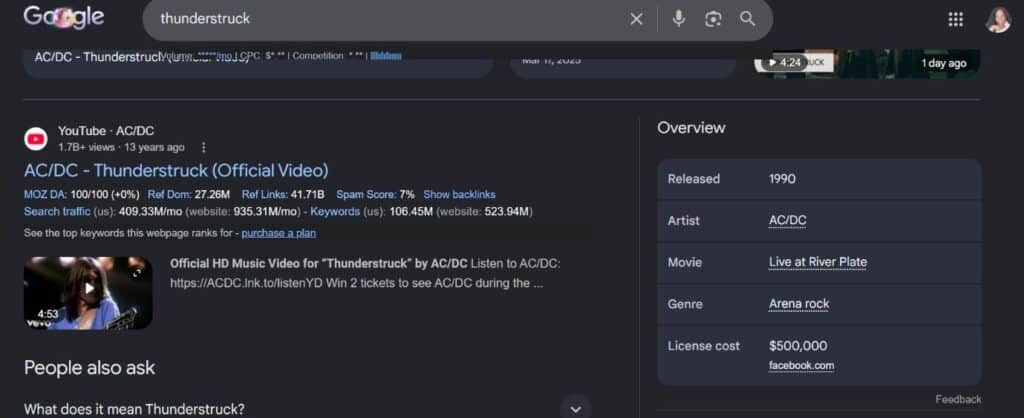
After looking up a few other big songs, I discovered the Licensing cost being included wasn’t typical of Google’s knowledge panel – which meant, it was probably a knowledge graph node, not a knowledge panel feature. So, I clicked through on the Facebook link listed in the knowledge panel and discovered a seemingly obscure stat listed in a 2022 Facebook post that got virtually no engagement.
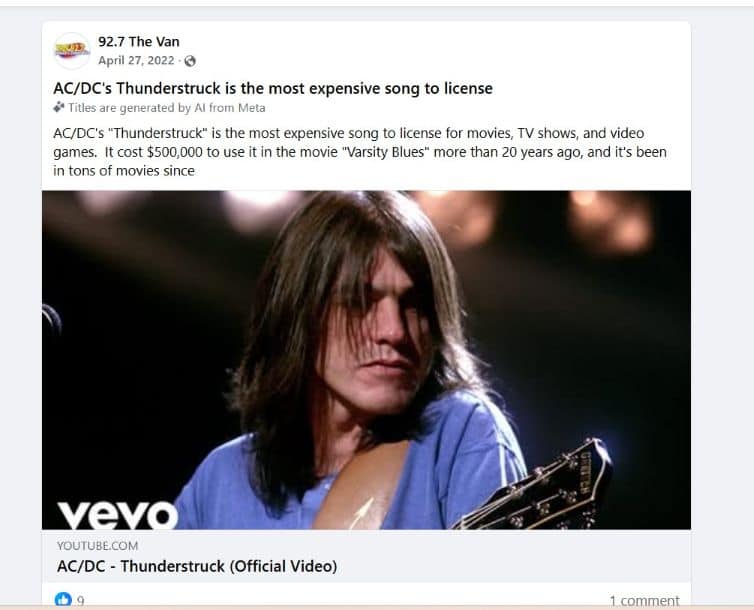
The stat itself was circulated in music industry publications in 2014 – eight years before this Facebook post went up. So, why would Google include a link to a Facebook post that wasn’t the canonical source of the information instead of just linking back to one of the older, high authority sources?
My take – extractability. The Facebook post was clean, clear, and delivered everything you needed in 39 words. Whereas the original article on that music website has the facts of the story scattered across a page that had a video loading, ads, and not enough good stuff showing up above the fold.
Eligibility earns you a seat at the table. Extractability moves you forward as a candidate for recommendability.
This is the layer that gets skipped — not because people don’t care about it, but because they don’t know it exists as a separate problem. The assumption is that if you’re visible and credible, you’ll be recommended. That’s not how it works. Recommendability is about the content architecture of trusted entities — specifically, whether your content is built in forms that AI systems can lift, use, and attribute without modification.
A machine constructing an answer needs to extract something usable. A definition it can quote. A process it can cite. An answer it can surface for a specific question. Content that is well-written and well-argued but not architecturally built for extraction gets passed over. Not because the machine doesn’t know you, not because it doesn’t trust you — because it can’t use what you built.
What Extractability Looks Like
Definitional snippets. Named concepts defined in two clean sentences — what the concept is, why it matters. This is the format AI systems pull for direct-answer queries. It also makes you the canonical source for that definition. When you name something and define it clearly, the machine has something to cite when the concept appears in a query.
Answer-first structure. Lead with the answer, then support it. Content that buries the answer in paragraph four gets passed over for content that leads with it. This isn’t stylistic preference — it’s how retrieval systems are built to work.
Named proprietary frameworks. A named concept with a consistent definition across all your content makes you the definitional source. The LEE model is an example of this. The Minimum Viable Knowledge Graph is another. Without the name, the idea floats unattributed.
Process architecture. Step-by-step sequences, numbered, one sentence per step. High surface rate for how-to queries and voice search.
Recency signals. Dated content that confirms the information is current. AI systems ask is this still true? not was this ever true? Update dates and refresh statistics when content is meaningfully revised.
The Extractability Failure Mode: The Branded Search Trap
Strong performance on searches for your name specifically. Thin or absent performance on unbranded category queries — the questions your ideal client is asking before they know you exist. The machine knows you. It trusts you. But when it’s constructing an answer to a question your brand should be answering, it reaches for someone whose content it can actually extract and use.
How to Diagnose Which COndition Is Missing
Before building strategy, find the gap. Building for the wrong tier wastes resources and produces results that feel random.
There’s a faster way to run this diagnostic than guessing: watch the language AI systems use when they respond to queries about you. Hedge language — she claims, according to their website, appears to specialize in, you should evaluate whether, limited track record — is the machine’s confidence score made visible. It’s not random phrasing. Each phrase maps to a specific node failure, which maps to a specific tier.
The Hedge Signal Diagnostic is the full framework for reading this language as structured data. Here’s the shortcut version mapped to LEE:
Identity Hedges Point to Legibility
Phrases like some sources describe, it’s unclear whether, there appear to be different versions mean the machine found you but can’t reconcile the signals into a coherent picture. That’s a Legibility gap — fragmented entity structure, inconsistent name or title across platforms, an About page that doesn’t introduce the person behind the business.
Credibility Hedges Point to Eligibility
Phrases like according to their website, they claim, I couldn’t find independent verification, you should evaluate whether mean the machine identified you but can’t corroborate what you’re claiming. That’s an Eligibility gap — the proof exists in your own content but nowhere else.
Capability Hedges Point to Extractability
If the machine describes you accurately and without identity hedging, but you’re invisible for unbranded category queries, that’s possibly an Extractability gap. The machine trusts you but can’t use your content to answer the questions it’s being asked.
Three Questions to Confirm Your Bottleneck
Can an AI system describe your business accurately without visiting your website? If no — or if the description is hedged, outdated, or confusing you with someone else — start with Legibility. Canonical bio, schema markup, About page that introduces the person, cross-platform alignment.
When an AI system mentions you, does it hedge? Phrases like she claims, according to their website, details may vary mean the machine found you but can’t confirm you. That’s an Eligibility gap. Build corroboration — guest articles, press mentions, podcast appearances, documented client outcomes with specifics.
Are you visible for unbranded queries — questions your ideal client is asking before they know your name? Branded search dominance with thin category presence is the Extractability signature. Add definitional snippets, name proprietary concepts, restructure section openings to lead with the answer.
The tiers are sequential but the diagnostic isn’t. Run the hedge signal check first — it usually tells you exactly where to look before you’ve asked a single strategic question.
Where The LEE Model Fits in Your AI Visibility Strategy
LEE is the destination map for the AI Foundations stack. The other pieces tell you how machines work and what breaks when things go wrong. This piece tells you where you’re trying to land.
The sequence: start with the canonical bio — the first brick of Legibility. Understand the three retrieval failures — what breaks at the ground level. Understand the three LLM behaviors — the terrain you’re navigating. Use the LEE Model to know which condition is the bottleneck before you build anything else. And if you want to see where this framework came from, the session where LEE landed is right here.

About the Author
Sorilbran Stone
AI Visibility Engineer and founder of Five-Talent Strategy House in Detroit. She helps founders and marketing teams build the infrastructure that gets them found — and accurately represented — in AI-generated answers.





